Flowcell QC summary (lanes 1,2,3,4,5)
| Date |
Flowcell |
Lane |
Platform Unit |
Readgroup |
Sample |
Library |
Type |
Project |
Genome |
Centre |
|
B04C2ABXX |
1 |
110311_SN553_0087_AB04C2ABXX_1 |
WTCHG_13229 |
samples |
4629/10 |
gDNA PE |
P100244 |
Mouse37 |
WTCHG |
|
B04C2ABXX |
2 |
110311_SN553_0087_AB04C2ABXX_2 |
WTCHG_13230 |
samples |
4630/10 |
gDNA PE |
P100244 |
Mouse37 |
WTCHG |
|
B04C2ABXX |
3 |
110311_SN553_0087_AB04C2ABXX_3 |
WTCHG_13231 |
samples |
4633/10 |
gDNA PE |
P100244 |
Mouse37 |
WTCHG |
|
B04C2ABXX |
4 |
110311_SN553_0087_AB04C2ABXX_4 |
WTCHG_13232 |
samples |
4634/10 |
gDNA PE |
P100244 |
Mouse37 |
WTCHG |
|
B04C2ABXX |
5 |
110311_SN553_0087_AB04C2ABXX_5 |
WTCHG_13233 |
samples |
4635/10 |
gDNA PE |
P100244 |
Mouse37 |
WTCHG |
| Lane |
Length |
Tiles |
Clusters PF |
% PF |
Yield (Mrd) |
Yield (Mb) |
Yield (Mb Q20) |
% Mapped |
% Coverage⊥ |
% Primer |
% Variants |
Mean cov.* |
% high cov.ℵ |
% dups |
% pair dups |
Link |
| 1.1 |
101 |
32 |
2410707 |
96.0 |
74.04 |
7477.71 |
7110.20 |
98.3 |
83.9 |
0.00 |
0.87 ± 0.00 |
3.21 |
11.76 |
1.48 |
0.58 |
lane |
| 1.2 |
101 |
32 |
2410707 |
96.0 |
74.04 |
7477.71 |
6880.48 |
98.0 |
83.9 |
0.00 |
0.93 ± 0.00 |
3.20 |
11.75 |
1.48 |
0.58 |
|
| 2.1 |
101 |
32 |
2405461 |
95.8 |
73.77 |
7450.89 |
7080.19 |
98.2 |
83.0 |
0.00 |
0.92 ± 0.00 |
3.24 |
13.67 |
1.32 |
0.44 |
lane |
| 2.2 |
101 |
32 |
2405461 |
95.8 |
73.77 |
7450.89 |
6866.15 |
97.9 |
82.9 |
0.00 |
0.98 ± 0.00 |
3.23 |
13.66 |
1.32 |
0.44 |
|
| 3.1 |
101 |
32 |
2419374 |
95.7 |
74.12 |
7486.00 |
7124.80 |
98.4 |
83.5 |
0.00 |
0.91 ± 0.29 |
3.23 |
12.98 |
1.38 |
0.53 |
lane |
| 3.2 |
101 |
32 |
2419374 |
95.7 |
74.12 |
7486.00 |
6912.56 |
98.1 |
83.5 |
0.00 |
0.95 ± 0.00 |
3.23 |
12.98 |
1.38 |
0.53 |
|
| 4.1 |
101 |
32 |
2386916 |
95.4 |
72.86 |
7358.37 |
7021.28 |
98.1 |
83.1 |
0.00 |
0.83 ± 0.00 |
3.19 |
11.16 |
1.68 |
0.81 |
lane |
| 4.2 |
101 |
32 |
2386916 |
95.4 |
72.86 |
7358.37 |
6804.12 |
97.9 |
83.1 |
0.00 |
0.88 ± 0.00 |
3.18 |
11.14 |
1.68 |
0.81 |
|
| 5.1 |
101 |
32 |
2325154 |
95.9 |
71.39 |
7210.23 |
6869.80 |
98.3 |
82.7 |
0.00 |
0.86 ± 0.00 |
3.14 |
12.63 |
1.38 |
0.50 |
lane |
| 5.2 |
101 |
32 |
2325154 |
95.9 |
71.39 |
7210.23 |
6660.20 |
98.0 |
82.6 |
0.00 |
0.92 ± 0.00 |
3.14 |
12.62 |
1.38 |
0.50 |
|
⊥ Fraction of reference that is covered at least once * Mean coverage is computed over regions that are covered at least once ℵ Proportion of reads in regions with coverage in top 0.1 percentile
Lane QC statistics and plots
| Lane |
% GC |
% GCmapped |
σpos(%GC) |
insert ± MAD |
% exonic |
% exon cov'ge |
%N |
maxpos %N |
%lowQ |
%lowQend |
avgQ |
| 1.1 |
41.1 ± 8.0 |
41.0 ± 8.0 |
0.35 |
370 ± 45 |
1.1 |
87.0 |
0.0 |
0.5 |
3.6 |
18.0 |
32.0 |
| 1.2 |
40.7 ± 8.2 |
40.7 ± 8.1 |
0.42 |
370 ± 45 |
1.1 |
86.8 |
0.1 |
0.0 |
6.2 |
29.9 |
30.1 |
| 2.1 |
41.4 ± 8.2 |
41.3 ± 8.2 |
0.36 |
374 ± 64 |
1.3 |
90.4 |
0.0 |
0.6 |
3.6 |
19.0 |
32.0 |
| 2.2 |
40.7 ± 9.6 |
41.2 ± 8.4 |
0.38 |
374 ± 64 |
1.3 |
90.6 |
0.1 |
0.0 |
6.1 |
29.2 |
30.1 |
| 3.1 |
41.3 ± 8.0 |
41.3 ± 8.0 |
0.34 |
377 ± 39 |
1.2 |
90.5 |
0.0 |
0.6 |
3.5 |
18.1 |
32.0 |
| 3.2 |
41.0 ± 8.4 |
41.1 ± 8.3 |
0.36 |
377 ± 39 |
1.2 |
90.4 |
0.1 |
0.0 |
5.9 |
28.3 |
30.2 |
| 4.1 |
41.2 ± 7.9 |
41.2 ± 7.8 |
0.50 |
365 ± 37 |
1.1 |
86.3 |
0.0 |
0.6 |
3.4 |
16.9 |
32.2 |
| 4.2 |
40.8 ± 8.2 |
40.8 ± 8.1 |
0.59 |
365 ± 36 |
1.1 |
85.9 |
0.1 |
0.1 |
5.8 |
28.1 |
30.2 |
| 5.1 |
41.3 ± 8.0 |
41.3 ± 8.0 |
0.38 |
376 ± 45 |
1.2 |
88.5 |
0.1 |
0.5 |
3.5 |
17.2 |
32.0 |
| 5.2 |
40.4 ± 9.4 |
41.0 ± 8.1 |
0.36 |
376 ± 45 |
1.2 |
88.4 |
0.2 |
0.1 |
5.9 |
28.1 |
30.2 |
G+C histogram∋
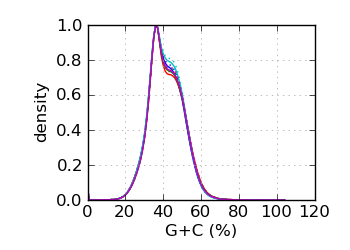 |
Insert size histogram∞
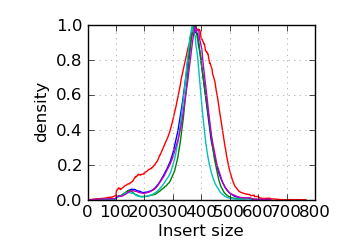 |
Mapped coverage by G+C℘
 |
|
Coverage histogram
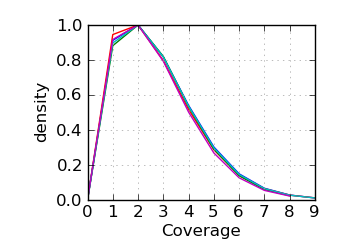 |
Exon/genome coverage distribution
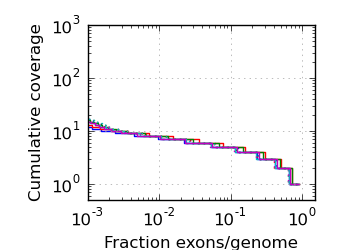 |
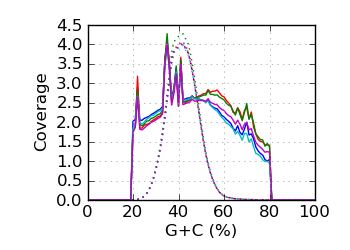
Genomic coverage by G+C∅
 |
|
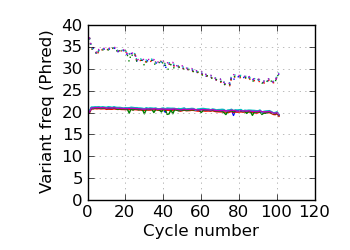
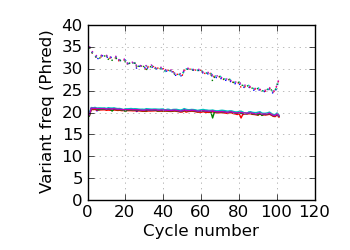
(Predicted) variants by cycle∇ (read 1)
 |
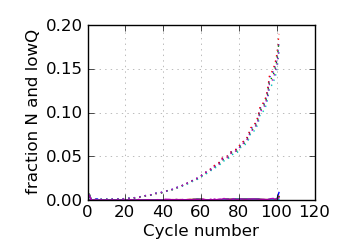
Fraction N/lowQ∋, read 1
 |
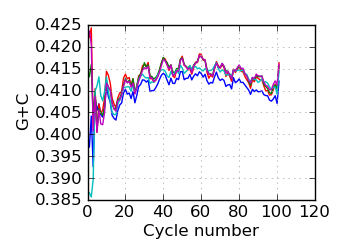
G+C by cycle (PF)∋, read 1
 |
|
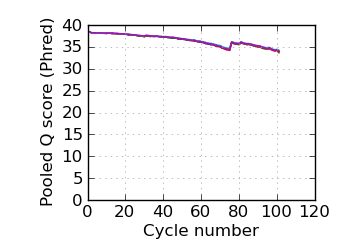
Mean Q by cycle∇, read 1
 |
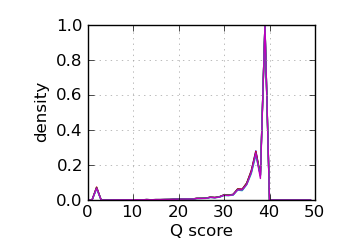
Q score histogram, read 1
 |
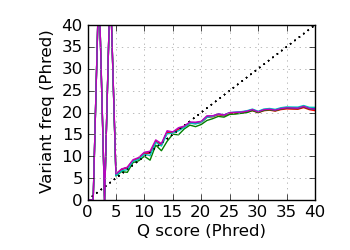
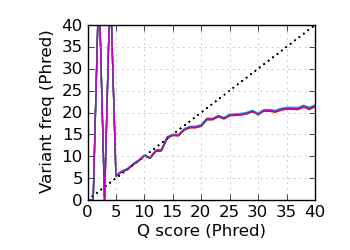
Variants by Q, read 1
 |
|
(Predicted) variants by cycle∇ (read 2)
 |
Fraction N/lowQ∋, read 2
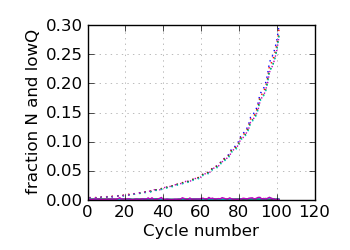 |
G+C by cycle (PF)∋, read 2
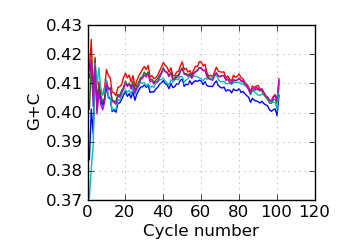 |
|
Mean Q by cycle∇, read 2
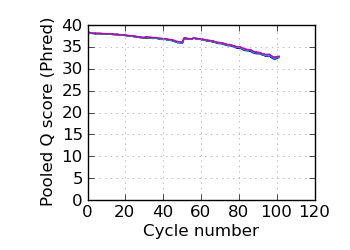 |
Q score histogram, read 2
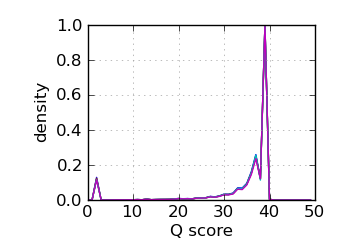 |
Variants by Q, read 2
 |
|
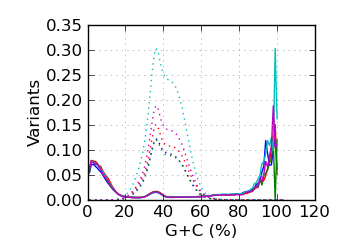
Variants by GC
 |
Log coverage histogram
 |
Legend
 |
∋ The Fraction N/Low Q plots, and dotted lines on the GC histogram plots, refer to all reads that have
passed chastity filters. If a reference genome was available, all others refer to mapped reads, otherwise
they too refer to chastity-filtered reads. The dotted lines in the fraction N/lowQ plot correspond to the
fraction of bases with quality score 4 or less. ∇ "Predicted variants" (dashed line) is the expected error frequency expressed as a Phred score,
and may be compared with the "Variants by cycle" graph (solid line). "Mean Q" (solid) is the numerical
mean Q score and is a measure of the average information content per read. These graphs use mapped reads only;
the dashed line in the Mean Q plot uses all (PF) reads. All four graphs are calculated on called bases with
Q Phred score above 4 only. ℘ Mapped coverage by G+C. The coverage was averaged over those genomic regions that were covered at least once.
Regions with coverage in the top 0.1 percentile were excluded; the dotted line shows results for all reads.
The G+C fraction was computed from read bases, excluding Ns and bases with quality below 4. ∅ Genomic coverage by G+C. The G+C fraction was computed from the reference genome, over the approximate fragment
Regions with coverage in the top 0.1 percentile were excluded.
The G+C histogram is shown as a dotted line (arbitrary Y scale). ∞ The insert size distribution is summarized by the median and median absolute deviation.
Tile QC statistics and plots
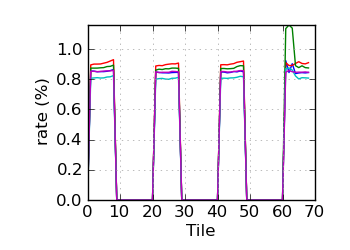
Variant rate by tile∝ (read 1)
 |
Raw/mapped yield by tile (read 1)
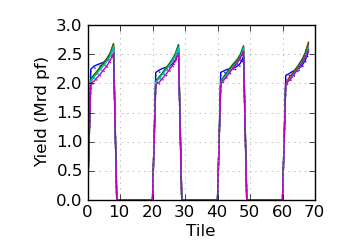 |
Fraction N/lowQ by tile (read 1)
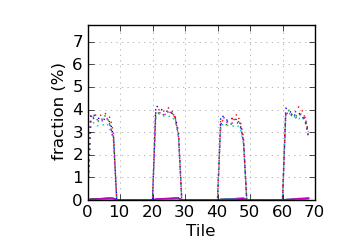 |
|
Variant rate by tile∝ (read 2)
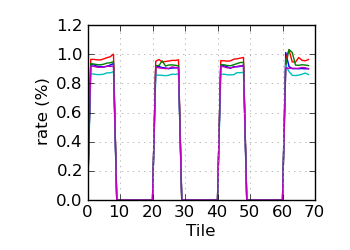 |
Raw/mapped yield by tile (read 2)
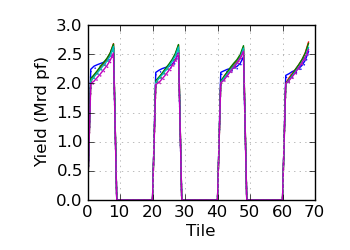 |
Fraction N/lowQ by tile (read 2)
 |
∝ HiSeq tiles are grouped in order: swathe 1 top; swathe 1 bottom; swathe 2 top; etc.
QC version: 2.1